
Gemma 3-270M: The Tiny AI Powerhouse Redefining On-Device Creativity
A responsive, Blogger-friendly longform report with embedded video and images.
1. What Is Gemma 3-270M?
Gemma 3-270M is a compact language model tuned for efficiency, responsiveness, and deployability. With a footprint that fits comfortably on modest CPUs and GPUs, it enables low-latency interactions, private on-device processing, and cost-effective experimentation for startups, classrooms, and hobbyists alike. While it is not meant to replace frontier-scale models in open-ended synthesis, it excels at guided creativity, structured drafting, and transformation tasks.
The balance of speed, controllability, and predictable behavior makes Gemma 3-270M a strong candidate for hybrid stacks: route simple, time-sensitive tasks locally; escalate complex, research-heavy queries to larger cloud models. This division of labor reduces costs while keeping UX snappy and reliable.
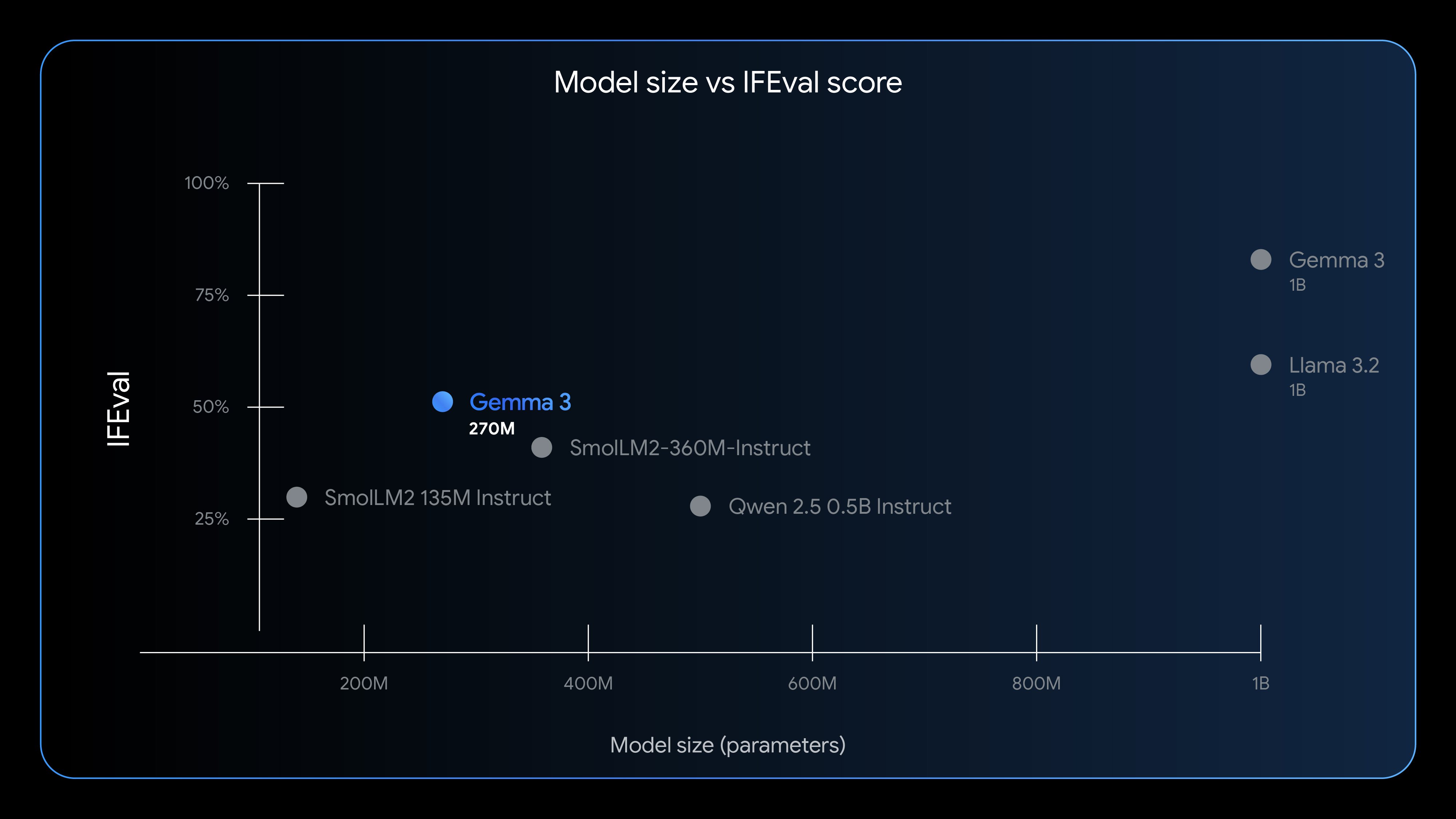
2. Why a Small Model Matters
- Latency: Instant feedback loops power better learning and creation.
- Cost: Serve more users with fewer resources, especially at scale.
- Privacy: On-device inference minimizes data exposure and supports compliance.
- Resilience: Edge apps continue working with intermittent connectivity.
In many workflows, a fast, predictable draft is more valuable than exhaustive knowledge expansion. Gemma 3-270M leans into that reality with a compact, focused design.
3. Watch the Demo
A short demonstration of bedtime story generation using a lightweight model.
4. Capabilities & Performance Signals
- Instruction following: Works best with concise, explicit directives.
- Style control: Maintains a steady tone in narrative and expository writing.
- Memory efficiency: Effective use of shorter contexts with careful prompts.
- Error locality: Mistakes are easy to correct with iterative guidance.

5. Practical Use Cases
Education & Family
Generate age-appropriate stories, reading passages, and vocabulary drills on devices used in classrooms and homes.
Productivity
Draft meeting notes, action items, FAQs, and support replies with consistent structures and tone.
Healthcare-adjacent (Non-diagnostic)
Template intake forms and patient guidance materials with human review and clear guardrails.
Embedded & Edge
Enable voice tips, kiosk prompts, and quick replies where connectivity is limited.
6. Developer Notes
- Use scaffolded prompts (outline first, expansion second).
- Post-process outputs for length, tone, and keywords.
- Route complex tasks to bigger models when confidence drops.
- Collect telemetry on edits to refine prompts and policies.
7. Conceptual Comparison
Massive models remain best for deep synthesis and long-range reasoning. Gemma 3-270M excels at bounded tasks requiring speed, predictability, and privacy. In a tiered architecture, both strengths compound.
8. Safety, Ethics, and Trust
Pair small models with content filters, age policies, and human review for sensitive contexts. Communicate limitations clearly and encourage feedback loops to catch issues early.
9. Looking Ahead
Expect continued gains from distillation, tokenizer improvements, and tool-use orchestration. Tiny models will power instant, private interactions while collaborating with cloud LLMs for heavy lifting.
10. Conclusion
Gemma 3-270M demonstrates how thoughtful design can make a small model feel big where it matters: responsive UX, predictable outputs, and on-device privacy. For educators, builders, and creators, it’s a practical ally for guided creativity and structured transformation.
Tip: Tap any image to view it larger.





.png)